Easy Machine Learning with PyCaret
This notebook shows a basic data science workflow using Pycaret - a new Python machine learning library



What is Pycaret
Pycaret is a new machine learning library that simplifies machine learning workflows. It is a high level library that sits on top of the most popular ML libraries - including general purpose libraries such as scikit-learn, tree-based such as lightgbm, xgboost and catboost, and NLP libraries such as nltk, gensim and spacy. In a sense pycaret shifts the focus from the implementation of mathematical algorithms to the implementation of ML workflow algorithms. Some of pycaret's functions, such as setup, create_model, predict_model, plot_model, are meant to perform a part of a typical data science project, while abstracting away from how the actual libraries underneath operate.
In this sense it is a little bit like build tools Maven and Gradle, tools that did not really care how the underlying tools in your project operated but focused instead on the workflow of producing build artifacts at the end. It is more of an ML workflow library with a set of opinionated workflow algorithms that guide how a data science project is created.
If you recall Maven artifacts are written in the scripting language most familiar to developers at the time - XML. Jupyter notebooks have the same familiarity for data scientists now - most data scientists use them. Pycaret is unapologetically intended for use in Jupyter notebooks - several of the functions output data to be displayed in a notebook as the data science project is being created. So for example, - when you load using get_data - it displays the data that was loaded in the notebook. This makes use of the IPython.display. Pycaret also uses ipywidgets to show tabs or other UI elements useful to assist a data scientist while working on a data science project. This is familiar to me - I have written a few Jupyter first libraries of my own
Getting Started
To get started install pycaret. In the best case scenario it's a simple as
pip install pycaret
For more details go to the Pycaret Install page
from pycaret.datasets import get_data
Included with pycaret is a small dataset called juice. This small dataset has information about 1070 purchases of Citrus Hill or Minute Maid orange juice. It is originally meant for R projects and so is hosted on rdrr.io, a site where searching for R related packages and data. Because the data is small, it is conveniently included in the pycaret library.
To get the data use the get_data function. This conveniently also displays the data in the notebook.
juice_dataset = get_data('juice')
The data seems complete and mostly numeric. The only weird thing about the data is that Id column, which we do not need because pandas generates an index for us. So let's drop it.
if 'Id' in juice_dataset:
juice_dataset = juice_dataset.set_index('Id')
Pandas Profiling Report
When you include the profile parameter get_data will output a pandas_profiling report created using the pandas_profile library. This gives a lot of information about the dataset and its features. Normally this helps in the data exploration phase of a data science project, but it's nice to also have it included in a function to get data.
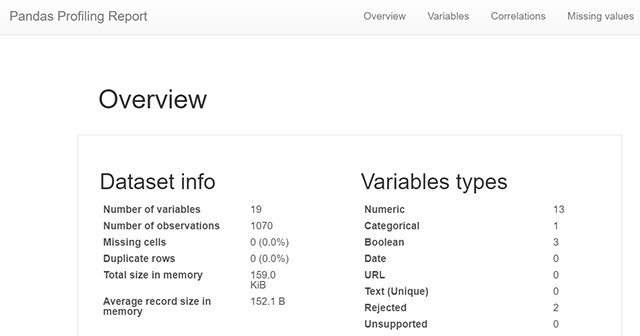
More about the orange juice dataset
We can find out more about the juice dataset by visiting the webpage at rdrr.io. Aternatively, we can grab the html from the site and convert the data description into a pandas dataframe. For this we will use a requests and BeautifulSoup. Here is that code.
#collapse
import pandas as pd
from bs4 import BeautifulSoup
import requests
pd.options.display.max_colwidth = 120
# 1. Grab the HTML from the website
r = requests.get('https://rdrr.io/cran/ISLR/man/OJ.html')
# 2. And convert it to a BeautifulSoup object
soup = BeautifulSoup(r.text)
def find_cells(soup, element):
for dl in soup.find_all('dl'):
for dt in dl.find_all('dt'):
# 3. Once we find the <dt> element return it along with the <dd> element
yield dt.text.strip(), dt.nextSibling.text.strip().replace('\n', ' ')
# 4. Convert the generator to a list of tuples
dt = list(find_cells(soup, 'dt'))
# 5. Now create a dataframe from the list of tuples
pd.DataFrame(dt, columns=['Feature','Description']).style.hide_index()
train = juice_dataset.sample(frac=0.80)
unseen_data = juice_dataset.drop(train.index).reset_index(drop=True)
train.shape, test.shape
The setup function
At the heart of Pycaret has a powerful machine learning pipeline that takes the input data and performs a huge part of the traditional data processing workflow. This pipeline is started by calling the setup function. setup initializes the environment, and creates the data transformation pipeline to prepare the data for model training.
It is a bit of a magic function - a lot of work is done inside this function and it has to be called before any of the pycaret model development is started. You call setup on your training data and tell it the target variable, and it will start preparing for model training. Importantly, it does some of the work that data scientists would be doing manually at this point, including making decisions about some of the preprocessing steps, such as apply PCA, or removing outliers etc. How well it does this is yet to be seen but it is certainly a big change to a data scientist's workflow if this can be done automatically. A lt of steps are done automatically by pycaret, as we will see later.
Regardless, setup displays a dataframe with information it discovers about the data's features and includes some of the decisions that were taken. This give a nice platform for ML modeling.
from pycaret.classification import *
juice_prep = setup(train, target='Purchase')
Compare Models
Once the data is prepared, a data scientist would now choose among candidate models. Again, there is another magic function compare_models which does this for you. This runs several models - 15 as shown below - on the data , and display key metrics to allow ypu to choose among the model types for the next step.
compare_models()
pd.read_csv('pycaret_models.csv').style.hide_index()
rc = create_model('ridge')
ridge_tuned = tune_model('ridge')
Plot Model
Another nice feature that pycaret provides is the ability to plot different charts that can tell you how your model performs. For our ridge classifier we can plot a Precision-Recall Curve using plot_model(plot='pr'). There are many different types of plots and it would be cool to try them out.
plot_model(ridge_tuned, plot = 'pr')

unseen_predictions = predict_model(ridge_tuned, data=unseen_data)
unseen_predictions[['Purchase', 'Label']]